快速开始¶
1. 前置依赖¶
在使用本组件前,请确认系统环境已安装相关依赖软件,清单如下:
| 依赖软件 | 说明 | 备注 |
|---|---|---|
| FISCO-BCOS | >= 2.0, 1.x版本请参考V0.5版本 | |
| Bash | 需支持Bash(理论上来说支持所有ksh、zsh等其他unix shell,但未测试) | |
| Java | JDK[1.8] | |
| Git | 下载的安装包使用Git | |
| MySQL | >= mysql-community-server[5.7] | |
| zookeeper | >= zookeeper[3.4] | 只有在进行集群部署的时候需要安装 |
2 部署步骤¶
2.1 获取工程代码¶
请按照WeBASE-Codegen-Monkey的操作手册进行操作。
如果你已经按照WeBASE-Codegen-Monkey的操作手册进行操作,那么恭喜,你将获得一个完整WeBASE-Collect-Bee工程目录。
WeBASE-Collect-Bee的工程使用gradle进行构建,是一个使用gradle进行多工程构建的SpringBoot工程。
├── ChangeLog.md
├── LICENSE
├── README.md
├── WeBASE-Collect-Bee-common
├── WeBASE-Collect-Bee-core
├── WeBASE-Collect-Bee-db
├── WeBASE-Collect-Bee-extractor
├── WeBASE-Collect-Bee-parser
├── build.gradle
├── gradle
├── gradlew
├── gradlew.bat
├── libs
├── settings.gradle
└── src
其中各个子工程的说明如下:
WeBASE-Collect-Bee-core是运行任务的主工程。
WeBASE-Collect-Bee-common 公共类库。
WeBASE-Collect-Bee-db 数据库相关的功能。
WeBASE-Collect-Bee-extractor 区块抽取相关的功能。
WeBASE-Collect-Bee-parser 区块解析相关的功能。
.
├── build.gradle
├── config
│ └── contract
├── dist
│ ├── WeBASE-Collect-Bee-WeBASE-Collect-Bee-core1.1.0.jar
│ ├── config
│ ├── monitor.sh
│ ├── start.sh
│ ├── stop.sh
│ └── webasebee-core.log
└── src
├── main
└── test
其中build.gradle为gradle的构建文件,config/contract目录存放了合约编译为Java的文件,src/main/resources下面存放了配置文件,dist是项目编译后生成的目录。
自动生成的Java代码一般位于src/main/java/com/webank/webasebee/*/generated;而合约编译后的文件除了会被存放到config/contract文件夹下以外,还会按照原有的package名称放入到src/main/java的路径下。
2.2 配置工程(更多高级配置)¶
当完整地按照WeBASE-Codegen-Monkey的操作手册进行操作获得WeBASE-Collect-Bee工程后,会得到WeBASE-Collect-Bee工程,主要的基础配置都将会在配置中自动生成,无需额外配置。但是,基于已生成的配置文件,你可以继续按照需求进行深入的个性化高级配置,例如配置集群部署、分库分表、读写分离等等。
在得到WeBASE-Collect-Bee工程后,进入WeBASE-Collect-Bee-core的目录:
cd WeBASE-Collect-Bee/WeBASE-Collect-Bee-core
主要的配置文件位于src/main/resources目录下。其中,application.properties包含了除部分数据库配置外的全部配置。 application-sharding-tables.properties包含了数据库部分的配置。
注意: 当修改完配置文件后,需要重新编译代码,然后再执行,编译的命令如下:
bash gradlew clean bootJar
导出数据范围的配置¶
配置文件位于 WeBASE-Collect-Bee/WeBASE-Collect-Bee-core/src/main/resources/application.properties
| 配置项 | 是否必输 | 说明 | 举例 | 默认值 |
|---|---|---|---|---|
| system.startBlockHeight | N | 设置导出数据的起始区块号,优先以此配置为准 | 1000 | 0 |
| system.startDate | N | 设置导出数据的起始时间,例如设置导出2019年元旦开始上链的数据;如已配置startBlockHeight,以导出数据起始区块号为准。支持的数据格式包括:yyyy-MM-dd HH:mm:ss 或 yyyy-MM-dd 或 HH:mm:ss 或 yyyy-MM-dd HH:mm 或 yyyy-MM-dd HH:mm:ss.SSS | 2019-01-01 | - |
单节点部署的配置¶
在选择单节点配置后,以下配置会自动生成。 单节点任务调度的配置,分布式任务调度的配置默认位于 WeBASE-Collect-Bee/WeBASE-Collect-Bee-core/src/main/resources/application.properties
#### 当此参数为false时,进入单节点任务模式
system.multiLiving=false
#### 多线程下载的分片数量,当完成该分片所有的下载任务后,才会统一更新下载进度。
system.crawlBatchUnit=100
集群部署的配置¶
多节点任务调度的配置,分布式任务调度的配置默认位于 WeBASE-Collect-Bee/WeBASE-Collect-Bee-core/src/main/resources/application.properties
#### 当此参数为true时,进入多节点任务模式
system.multiLiving=true
#### zookeeper配置信息,ip和端口
regcenter.serverList=ip:port
#### zookeeper的命名空间
regcenter.namespace=namespace
#### prepareTaskJob任务:主要用于读取当前区块链块高,将未抓取过的块高存储到数据库中。
#### cron表达式,用于控制作业触发时间
prepareTaskJob.cron=0/5 * * * * ?
### 分片总数量
prepareTaskJob.shardingTotalCount=1
#### 分片序列号和参数用等号分隔,多个键值对用逗号分隔,分片序列号从0开始,不可大于或等于作业分片总数
prepareTaskJob.shardingItemParameters=0=A
#### dataflowJob任务: 主要用于执行区块下载任务
dataflowJob.cron=0/5 * * * * ?
### 分片总数量
dataflowJob.shardingTotalCount=3
#### 分片序列号和参数用等号分隔,多个键值对用逗号分隔,分片序列号从0开始,不可大于或等于作业分片总数
dataflowJob.shardingItemParameters=0=A,1=B,2=C
数据库配置解析,数据库的配置默认位于 WeBASE-Collect-Bee/WeBASE-Collect-Bee-core/src/main/resources/application-sharding-tables.properties
分库分表的配置¶
实践表明,当区块链上存在海量的数据时,导出到单个数据库或单个业务表会对运维造成巨大的压力,造成数据库性能的衰减。 一般来讲,单一数据库实例的数据的阈值在1TB之内,单一数据库表的数据的阈值在10G以内,是比较合理的范围。
如果数据量超过此阈值,建议对数据进行分片。将同一张表内的数据拆分到同个数据库的多张表。
spring.shardingsphere.datasource.names=ds
# 定义数据源ds属性
spring.shardingsphere.datasource.ds.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds.jdbc-url=jdbc:mysql://[ip]:3306/[db]?autoReconnect=true&useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds.username=
spring.shardingsphere.datasource.ds.password=
#将block_detail_info取模5路由到5张表
spring.shardingsphere.sharding.tables.block_detail_info.actual-data-nodes=ds.block_detail_info_$->{0..4}
spring.shardingsphere.sharding.tables.block_detail_info.table-strategy.inline.sharding-column=block_height
spring.shardingsphere.sharding.tables.block_detail_info.table-strategy.inline.algorithm-expression=block_detail_info_$->{block_height % 5}
spring.shardingsphere.sharding.tables.block_detail_info.key-generator-column-name=pk_id
将同一张表内的数据拆分到多个数据库的多张表。
# 配置所有的数据源,如此处定义了ds,ds0,ds1 三个数据源,对应三个库
spring.shardingsphere.datasource.names=ds,ds0,ds1
# 设置默认的数据源
spring.shardingsphere.sharding.default-datasource-name=ds
# 定义数据源ds
spring.shardingsphere.datasource.ds.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds.jdbc-url=jdbc:mysql://[ip]:3306/[db]?autoReconnect=true&useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds.username=
spring.shardingsphere.datasource.ds.password=
# 定义数据源ds0
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://[ip]:3306/[db]?autoReconnect=true&useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds0.username=
spring.shardingsphere.datasource.ds0.password=
# 定义数据源ds1
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://[ip]:3306/[db]?autoReconnect=true&useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds1.username=
spring.shardingsphere.datasource.ds1.password=
# 定义数据库默认分片的数量,此处分为2,以block_height取模2来路由到ds0或ds1
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=block_height
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{block_height % 2}
# 定义block_detail_info的分表策略,以block_height取模2来路由到ds0的block_detail_info0或ds1的block_detail_info1
spring.shardingsphere.rules.sharding.tables.block_detail_info.actual-data-nodes=ds0.block_detail_info0,ds1.block_detail_info1
spring.shardingsphere.rules.sharding.tables.block_detail_info.table-strategy.inline.sharding-column=block_height
spring.shardingsphere.rules.sharding.tables.block_detail_info.table-strategy.inline.algorithm-expression=block_detail_info$->{block_height % 2}
spring.shardingsphere.rules.sharding.tables.block_detail_info.key-generator-column-name=pk_id
spring.shardingsphere.rules.sharding.tables.block_task_pool.actual-data-nodes=ds0.block_task_pool0,ds1.block_task_pool1
spring.shardingsphere.rules.sharding.tables.block_task_pool.table-strategy.inline.sharding-column=block_height
spring.shardingsphere.rules.sharding.tables.block_task_pool.table-strategy.inline.algorithm-expression=block_task_pool$->{block_height % 2}
spring.shardingsphere.rules.sharding.tables.block_task_pool.key-generator-column-name=pk_id
# 打印sql日志的开关
spring.shardingsphere.props.sql.show=true
数据库读写分离的配置:¶
数据库读写分离的主要设计目标是让用户无痛地使用主从数据库集群,就好像使用一个数据库一样。读写分离的特性支持往主库写入数据,往从库查询数据,从而减轻数据库的压力,提升服务的性能。
注意,本组件不会实现主库和从库的数据同步、主库和从库的数据同步延迟导致的数据不一致、主库双写或多写。
##### 配置一主两从的数据库
spring.shardingsphere.datasource.names=master,slave0,slave1
spring.shardingsphere.datasource.master.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/master
spring.shardingsphere.datasource.master.username=
spring.shardingsphere.datasource.master.password=
spring.shardingsphere.datasource.slave0.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave0.url=jdbc:mysql://localhost:3306/slave0
spring.shardingsphere.datasource.slave0.username=
spring.shardingsphere.datasource.slave0.password=
spring.shardingsphere.datasource.slave1.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.url=jdbc:mysql://localhost:3306/slave1
spring.shardingsphere.datasource.slave1.username=
spring.shardingsphere.datasource.slave1.password=
spring.shardingsphere.masterslave.name=ms
spring.shardingsphere.masterslave.master-data-source-name=master
spring.shardingsphere.masterslave.slave-data-source-names=slave0,slave1
spring.shardingsphere.props.sql.show=true
数据库读写分离+分库分表的配置:¶
spring.shardingsphere.datasource.names=master,slave0
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://[ip]:3306/test0?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.master.username=
spring.shardingsphere.datasource.master.password=
spring.shardingsphere.datasource.slave0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave0.jdbc-url=jdbc:mysql://[ip]:3306/test1?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.slave0.username=
spring.shardingsphere.datasource.slave0.password=
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=master
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=slave0
spring.shardingsphere.sharding.tables.activity_activity.actual-data-nodes=ds0.block_tx_detail_info$->{0..1}
spring.shardingsphere.sharding.tables.activity_activity.table-strategy.inline.sharding-column=block_height
spring.shardingsphere.sharding.tables.activity_activity.table-strategy.inline.algorithm-expression=block_tx_detail_info$->{block_height % 2}
2.3 编译代码并运行程序¶
但是如果你对WeBASE-Collect-Bee的工程配置或代码进行了深度定制,当修改完成后,可参考以下步骤进行编译和启动, 这样可以省去重新下载代码库和重新生成代码,而且避免了你的个性化改动被覆盖:
cd WeBASE-Collect-Bee
bash gradlew clean bootJar
cd WeBASE-Collect-Bee-core/dist
chmod +x *.jar
chmod +x *.sh
bash start.sh
tail -f *.log
# 停止进程
bash stop.sh
当然,你也可以使用supervisor来守护和管理进程,supervisor能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。 它是通过fork/exec的方式把这些被管理的进程当作supervisor的子进程来启动,这样只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去即可。 也实现当子进程挂掉的时候,父进程可以准确获取子进程挂掉的信息的,可以选择是否自己启动和报警。 supervisor还提供了一个功能,可以为supervisord或者每个子进程,设置一个非root的user,这个user就可以管理它对应的进程。
supervisor的安装与部署可以参考 WeBASE-Codegen-Monkey 附录6的说明文档。
2.4 检查运行状态及退出¶
2.4.1 检查程序进程是否正常运行¶
ps -ef |grep WeBASE-Collect-Bee
如果看到如下信息,则代表进程执行正常:
app 21980 24843 0 15:23 pts/3 00:00:44 java -jar WeBASE-Collect-Bee1.0.2-SNAPSHOT.jar
2.4.2 检查程序是否已经正常执行¶
当你看到程序运行,并在最后出现以下字样时,则代表运行成功:
Hibernate: select blockheigh0_.pk_id as pk_id1_2_, blockheigh0_.block_height as block_he2_2_, blockheigh0_.event_name as event_na3_2_, blockheigh0_.depot_updatetime as depot_up4_2_ from block_height_info blockheigh0_ where blockheigh0_.event_name=?
Hibernate: select blockheigh0_.pk_id as pk_id1_2_, blockheigh0_.block_height as block_he2_2_, blockheigh0_.event_name as event_na3_2_, blockheigh0_.depot_updatetime as depot_up4_2_ from block_height_info blockheigh0_ where blockheigh0_.event_name=?
Hibernate: select blockheigh0_.pk_id as pk_id1_2_, blockheigh0_.block_height as block_he2_2_, blockheigh0_.event_name as event_na3_2_, blockheigh0_.depot_updatetime as depot_up4_2_ from block_height_info blockheigh0_ where blockheigh0_.event_name=?
2.4.3 检查数据是否已经正常产生¶
你也可以通过DB来检查,登录你之前配置的数据库,看到自动创建完表的信息,以及表内开始出现数据内容,则代表一切进展顺利。如你可以执行以下命令:
# 请用你的配置信息替换掉[]里的配置,并记得删除[]
mysql -u[用户名] -p[密码] -e "use [数据库名]; select count(*) from block_detail_info"
如果查询结果非空,出现类似的如下记录,则代表导出数据已经开始运行:
+----------+
| count(*) |
+----------+
| 633 |
+----------+
2.4.4 停止导入程序¶
bash stop.sh
2.5 监控数据导出¶
在WeBASE-Collect-Bee工程最终编译后,生成的dist目录会有个monitor.sh脚本. 执行该脚本可以用来监控数据导出服务是否正常启动或者数据导出是否正常工作。
2.5.1 个性化配置¶
打开monitor.sh,可以修改相关的个性化配置:
# WeBASE-Collect-Bee服务启动的IP地址
ip=127.0.0.1
# WeBASE-Collect-Bee服务启动的端口
port=8082
# 数据导出的进度落后于链高度的报警阈值;如当前进度落后当前链高度达到20个以上,输出报警日志。
threshold=20
# 当链高度增长,数据导出完成块高的报警阈值;如当前块高增长,但完成导出的区块数量增长小于等于1.
warn_number=1
2.5.2 使用¶
monitor.sh脚本可以直接执行.
./monitor.sh
block height now is 47
download number is 48
Now have 0 blocks to depot
OK! to do blocks is lesss than 20
OK! done blocks from 48 to 48, and height is from 48 to 48
2.5.3 提示¶
OK! to do blocks is lesss than $threshold 区块导出总体进度正常.
OK! done blocks from $prev_done to $b, and height is from $prev_height to $a 上个时间周期区块导出进度正常.
ERROR! $todo_blocks:the block height is far behind. 区块总体下载进度异常.
ERROR! Depot task stuck in trouble, done block is $prev_done to $b , but block height is from $prev_height to $a 上个时间周期数据导出进度异常.
ERROR! Get block height error. 获取块高失败.
ERROR! Get done block count error. 获取区块下载数量失败。
2.5.4 配置crontab¶
建议将monitor.sh添加到crontab中,设置为每分钟执行一次,并将输出重定向到日志文件。可以日常扫描日志中的ERROR!字段就能找出节点服务异常的时段, 也可以在节点挂掉情况下及时将节点重启。在crontab的配置可以参考如下:
*/1 * * * * /data/app/fisco-bcos/WeBASE-Collect-Bee/dist/monitor.sh >> /data/app/fisco-bcos/WeBASE-Collect-Bee/dist/monitor.log 2>&1
用户在实际中使用时将monitor.sh、monitor.log的路径修改即可。
3. 可视化监控程序安装和部署¶
3.1 安装软件¶
首先,请安装docker,docker的安装可参考docker安装手册
等docker安装成功后,请下载grafana:
docker pull grafana/grafana
如果你是使用sudo用户安装了docker,可能会提示『permission denied』的错误,建议执行:
sudo docker pull grafana/grafana
3.2 启动grafana¶
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=grafana-clock-panel,grafana-simple-json-datasource" grafana/grafana
grafana将自动绑定3000端口并自动安装时钟和Json的插件。
3.4 添加MySQL数据源¶
在正常登录成功后,如图所示,选择左边栏设置按钮,点击『Data Sources』, 选择『MySQL』数据源
 [添加步骤]
[添加步骤]
随后按照提示的页面,配置 Host, Database, User 和 Password等。
3.5 导入Dashboard模板¶
WeBASE-Codegen-Monkey会自动生成数据的dashboard模板,数据的路径位于:WeBASE-Collect-Bee/src/main/scripts/grafana/default_dashboard.json
请点击左边栏『+』,选择『import』,点击绿色按钮『Upload .json File』,选择刚才的WeBASE-Collect-Bee/src/main/scripts/grafana/default_dashboard.json文件
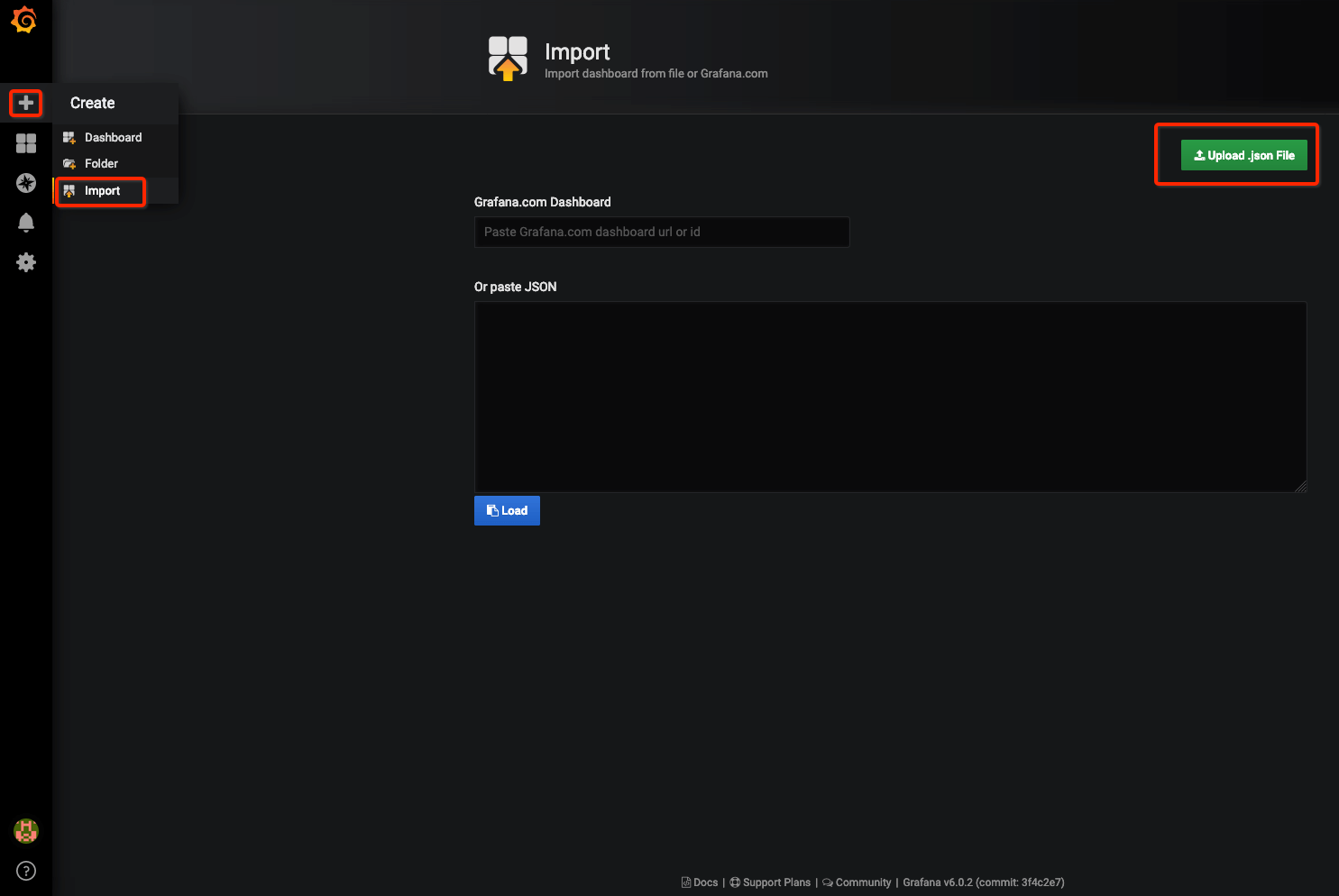 [导入步骤]
[导入步骤]
最后,点击『import』按钮。
如果导入成功,dashboards下面会出现『FISCO-BCOS区块链监控视图』
您可以选择右上方的时间按钮来选择和设置时间范围及刷新时间等。
您也可以选中具体的页面组件进行编辑,自由地移除或挪动组件的位置,达到更好的使用体验。
更多关于Grafana的自定义配置和开发文档,可参考 Grafana官方文档
4. 开启可视化的API文档和功能性测试¶
WeBASE-Collect-Bee默认集成了swagger的插件,支持通过可视化的控制台来发送交易、生成报文、查看结果、调试交易等。
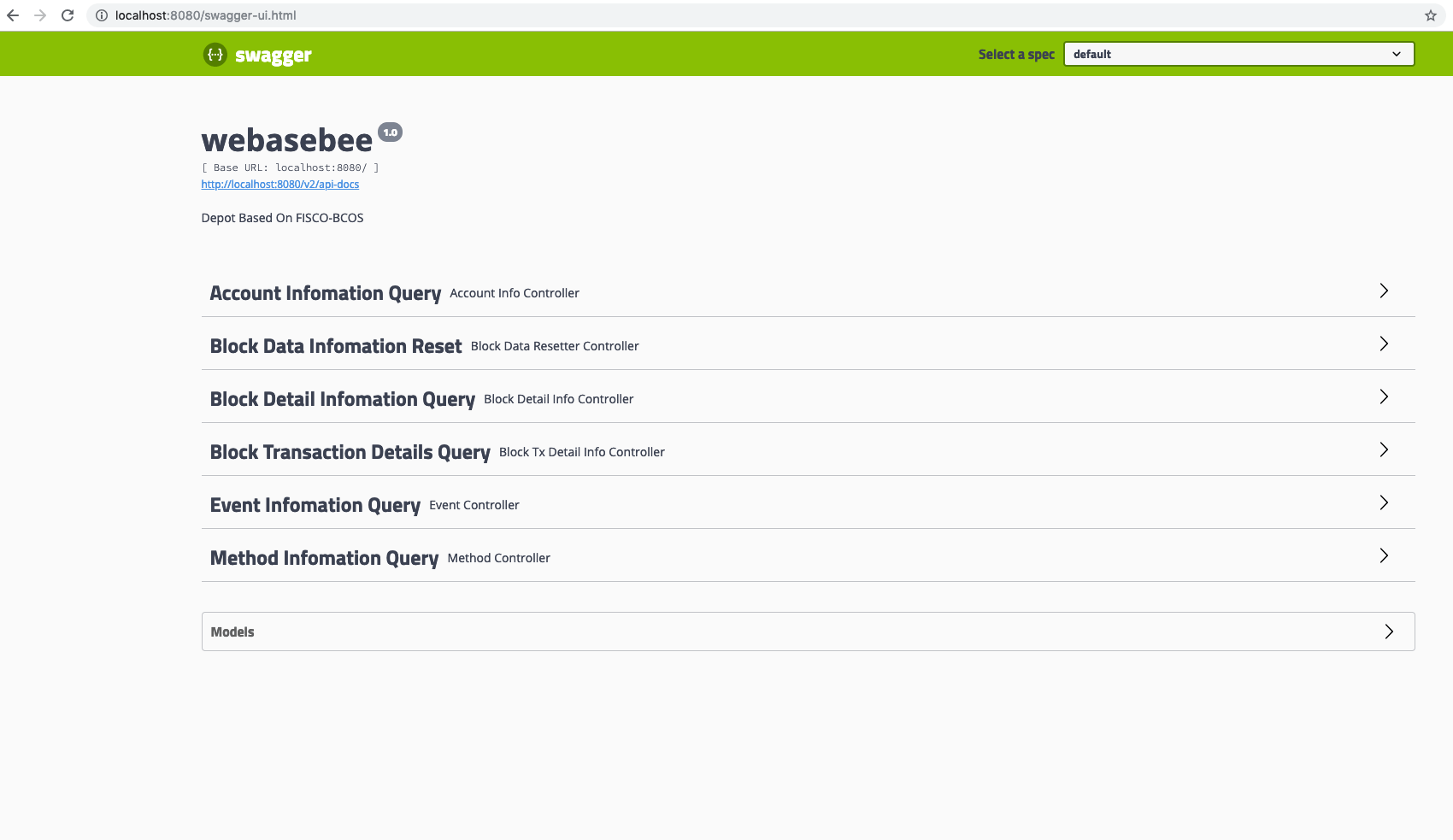 [swagger控制台]
[swagger控制台]
请注意, swagger插件仅推荐在开发或测试环境调试使用,在正式上生产环境时,请关闭此插件
swagger可使用配置开启或关闭,配置文件修改及操作可参考2.2章节。
## 打开swagger
button.swagger=on
## 关闭swagger
button.swagger=off
4.1 查看API文档:¶
请在你的浏览器打开此地址:
http://your_ip:port/swagger-ui.html
例如,当你在本机运行了WeBASE-Collect-Bee,且未修改默认的5200端口,则可以访问此地址:
http://localhost:5200/swagger-ui.html
此时,你可以看到上述页面,可以看到页面主要包括了http请求页面和数据模型两部分。
4.2 使用swagger发送具体的交易:¶
选择点击对应的http请求集,可以点开相关的http请求。此时,你可以选择点击“try it out”,手动修改发送的Json报文,点击“Excute”按钮,即可发送并查收结果。
我们以查询区块信息为例,如下列图所示:
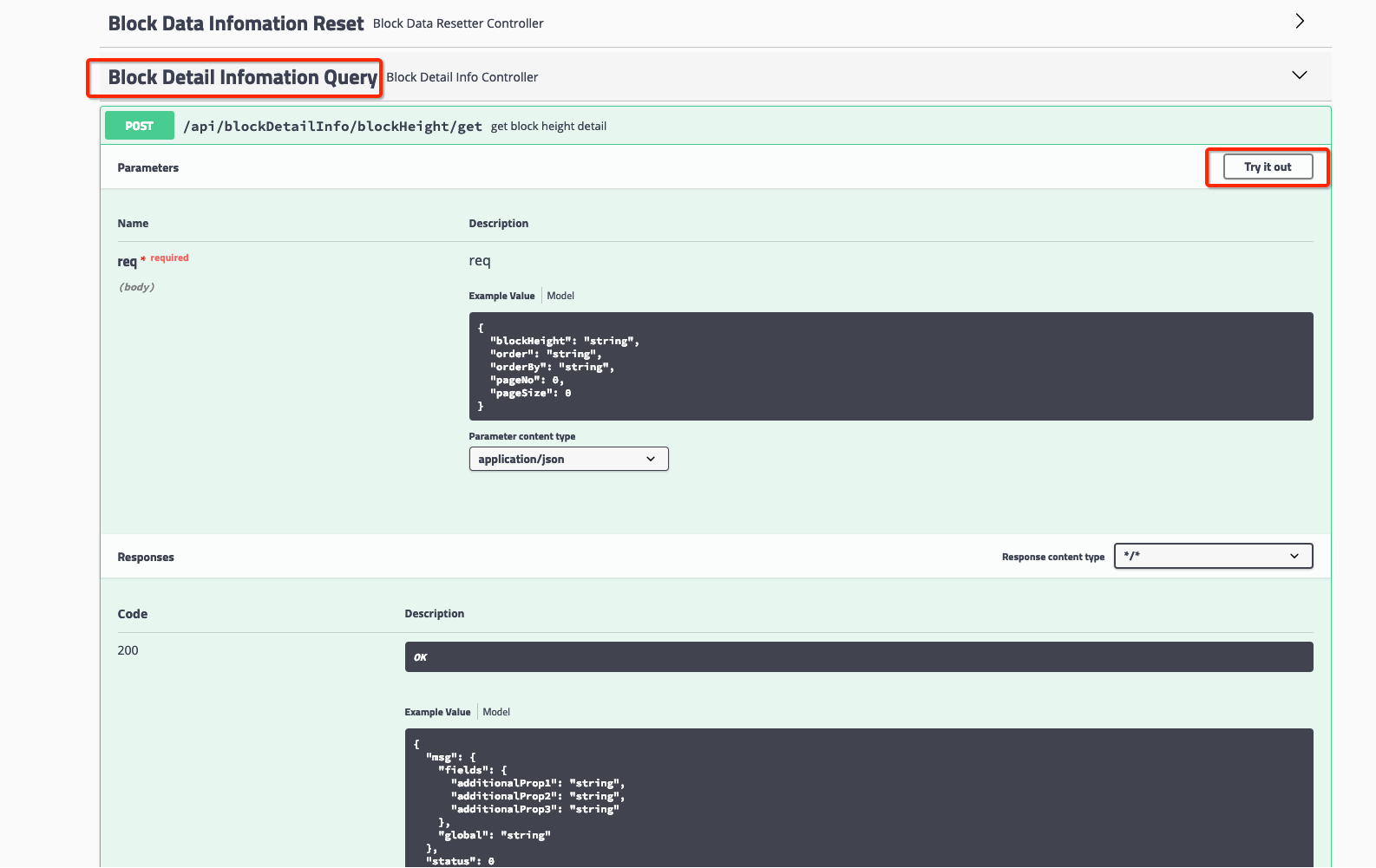 [选择请求]
[选择请求]
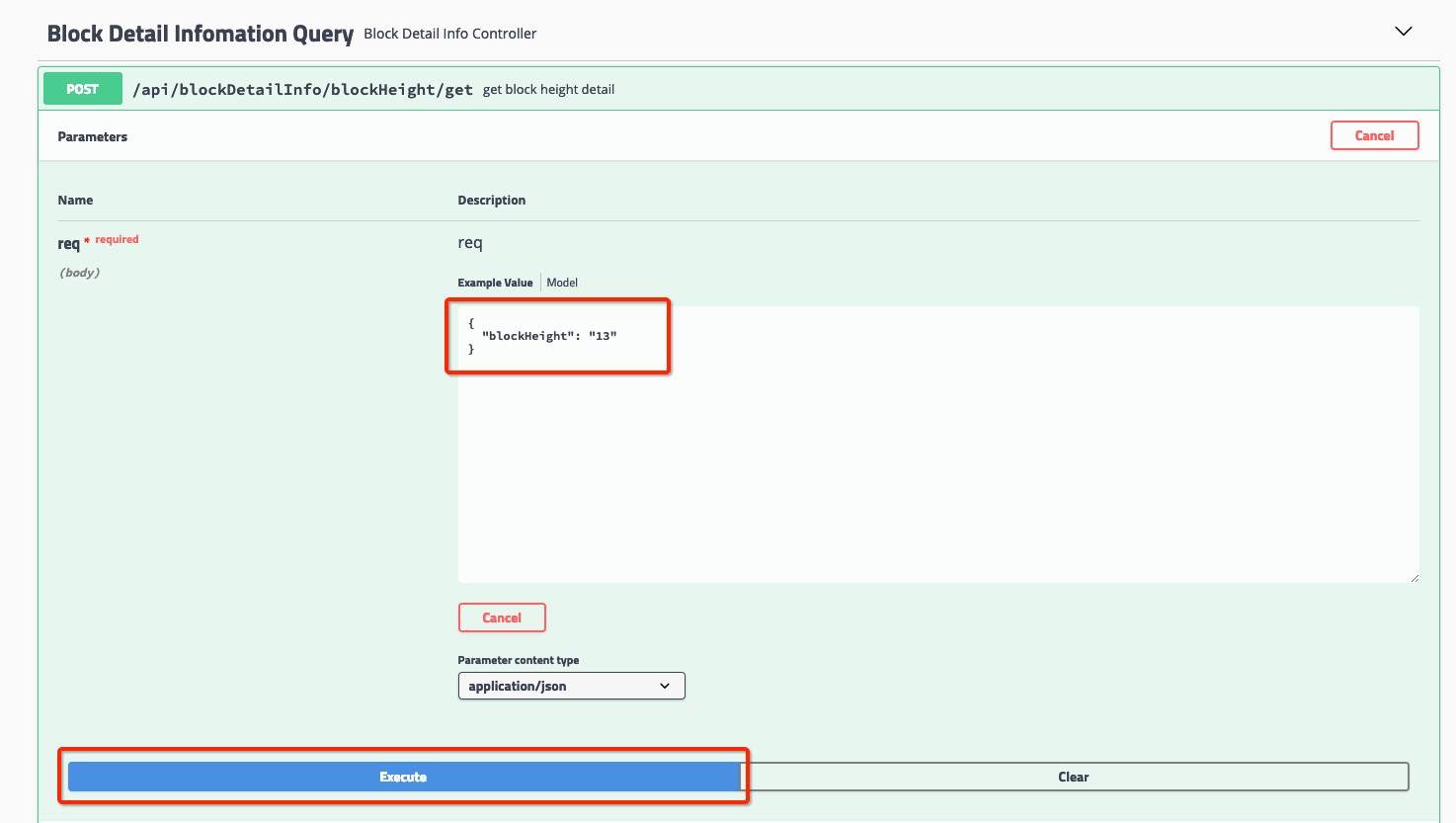 [编辑报文]
[编辑报文]
 [查收结果]
[查收结果]